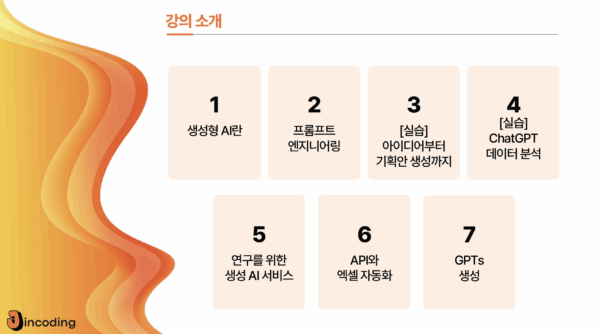
- 활용 기술: Python, Huggingface, Streamlit
- 교육 일자 및 기간: 2024년 4월 29일 | 2일간 진행
대규모 언어 모델(LLM)이 산업 현장에 본격적으로 도입되면서, 이를 효과적으로 활용하고 커스터마이즈하기 위한 기술 교육의 수요가 빠르게 증가하고 있습니다. 최근 진행된 ‘HuggingFace를 이용한 LLM Fine-tuning’ 두 일간의 실무 중심 교육은 이러한 흐름에 발맞추어 실제 업무 적용이 가능한 HuggingFace 생태계 활용법과 LLM 파인튜닝 기법 전반을 다룬 유익한 콘텐츠로 구성돼 주목을 받았습니다.

LLM을 이해하고 사용하기 위한 출발점 – Transfer Learning과 Fine-tuning
첫째 날 강의는 LLM을 실무에 적극 도입하고자 하는 개발자를 위한 Transfer Learning의 개념 소개로 시작됐습니다. Sentiment Analysis, Summarization, Translation 등 NLP 주요 업무(Task-specific)에 따라 LLM을 어떻게 최적화할 수 있는지를 학습하며, Instruction 기반 Fine-tuning과 In-context learning 방식의 차이를 비교 분석했습니다.
이어진 내용에서는 HuggingFace의 Model, Dataset, Space 기능을 중심으로 어떤 모델이 어떤 데이터셋과 함께 사용될 수 있는지, 그리고 직접 모델을 실행해볼 수 있는 웹 데모 및 리더보드를 탐색하는 방법 등을 체계적으로 설명했습니다.
핵심 도구의 마스터 – Transformers 라이브러리의 실전 활용법
모델의 실질적인 구성 요소인 Tokenizer, Model 구조, Post-processing 단계에 대한 설명과 함께, HuggingFace의 pipeline() 함수를 통해 불과 몇 줄의 코드로 강력한 NLP 기능을 구현할 수 있는 방법이 소개됐습니다. Sentence Classification을 위한 BERT 모델부터 Text Generation을 위한 mT5 모델까지, 한국어 데이터셋을 활용한 다양한 Fine-tuning 사례는 실무 적용을 염두에 둔 수강생들의 큰 관심을 받았습니다.
실습에서 체득한 기술 – 직접 모델을 터치해보다
기술을 배우는 가장 효과적인 방법은 직접 손으로 실험해보는 것입니다. 이번 교육은 이 원칙을 충실히 반영하여 HuggingFace의 datasets와 tokenizer를 활용한 전처리 실습, Transformer 모델을 불러와 BERT 기반 감성 분류 모델을 학습, tensorboard를 통해 시각화하여 모델을 점검하는 등 실무에서 바로 사용할 수 있는 환경과 코드를 다뤘습니다.
또한, mT5 모델을 기반으로 한 한국어 뉴스 기사 제목 생성 실습을 통해 자연어 생성의 원리와 결과 평가(Rouge Score)까지 전반적인 흐름을 체험했습니다.
LLM 생성 품질을 좌우하는 디코딩 전략 – Decoding 파라미터 완전 이해
둘째 날에는 LLM 기반 텍스트 생성에서 핵심이 되는 **Decoding 전략**들을 집중적으로 다뤘습니다. Beam Search, Greedy Decoding, Random Sampling 등 디코딩 방식의 차이와, `temperature`, `top_p`, `no_repeat_ngram_size` 등의 파라미터가 결과물의 다양성과 품질에 어떤 영향을 미치는지를 구체적인 코드 예시 및 실험 중심으로 배웠습니다.
자원 효율화를 위한 강력한 솔루션 – PEFT와 LoRA 실습
최근 LLM 학습 과정의 높은 연산비용 문제를 해결하기 위한 대안으로 주목받고 있는 것이 PEFT(Parameter Efficient Fine-tuning)입니다. 이번 세션에서는 HuggingFace의 PEFT 모듈을 이용해 대표적인 기법인 LoRA(Low-Rank Adaption)의 원리와 구현 방법을 확인할 수 있었습니다. 파라미터 일부만 학습에 참여시켜 최적의 성능을 빠르게 확보하는 LoRA의 장점은, 특히 GPU 자원이 제한적인 환경에서도 Fine-tuning을 가능케 한다는 점에서 실무자들에게 큰 인사이트를 제공했습니다.
실습 시간에는 실제로 LoRA를 활용해 기존 모델을 수정하고 성능 변화를 확인해보며 PEFT 기법의 효과를 직접 체험해보는 시간이 마련됐습니다.
학습 이후 실무로 연결되는 기술 성장
이번 ‘HuggingFace를 이용한 LLM Fine-tuning’ 교육은 단순한 이론 전달을 넘어, 실제 현업에서 LLM을 어떻게 활용할 수 있는지 방향성을 제시하고 직접 구성해보는 기회를 제공했습니다. 참가자들은 HuggingFace Hub의 자동화된 Fine-tuning 기능부터 텍스트 생성의 정교한 제어, 효율적인 파인튜닝 전략까지 폭넓은 AI 활용 지식을 얻었습니다.
특히, 한국어 데이터셋을 활용해 실습이 진행되었고, 코드 수준까지 내려가 실제 AI 서비스를 적용하기 위한 기반 기술을 익힐 수 있었다는 점에서 기술 내재화를 목표로 하는 조직에게 매우 실질적인 투자였다는 평가를 받았습니다.
AI 기술 도입을 고려하는 기업이라면, 이런 교육이 필요합니다
AI 기술 도입이 더 이상 선택이 아닌 시대, HuggingFace 기반 LLM Fine-tuning 실무 교육은 조직 내 기술 리더들을 위한 필수 루트입니다. 효율적인 개발, 빠른 프로토타입 제작, 고품질 AI 서비스 기획을 위해서라도 HuggingFace 생태계를 자유롭게 다룰 수 있는 역량은 곧 경쟁력으로 직결됩니다.
향후 인공지능을 활용해 내부 업무 자동화를 추진하거나 새롭게 AI 서비스를 기획하고 있다면, 이런 실무 중심 교육 과정이 AI를 활용 가능한 기술로 바꾸는 실질적 초석이 될 것입니다.